文档扫描OCR识别的安装

 最新推荐文章于 2024-03-25 09:59:31 发布
最新推荐文章于 2024-03-25 09:59:31 发布
 阅读量559
阅读量559
 收藏
2
收藏
2


 点赞数
1
点赞数
1



步骤
先下载tesseract,选择一个版本即可
tesseract地址
如果C盘有限,可以将默认的地址C盘改为D盘即可例如:
D:\Program Files \Tesseract-OCR
window中命令行运行
1.如果需要在window命令行中运行,需要配置环境变量
在用户变量和系统变量的path中,都新增一个tesseract的路径,该路径为上面的安装路径。

2.通过在命令行输入tesseract -v,若得到相应版本信息则配置成功。

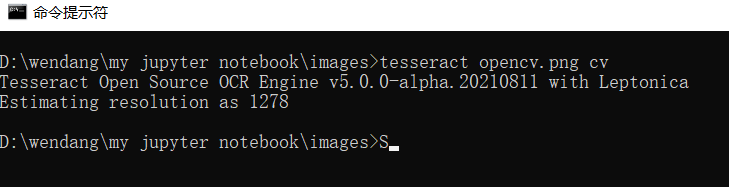
3.测试图片,cd到图片所在位置,用 tesseract (图像名称,包括后缀名,例如opencv.png) (txt文件名例如cv,系统会自动在本文件夹内产生一个txt文件)命令测试。

python 运行,比如jupyter notebook

1还需要在终端下安装pip install pytesserac
2.修改pytesseract.py中的tesseract_cmd指向的路径
tesseract_cmd = r’D:\Program Files \Tesseract-OCR\tesseract.exe’

如果不行,重启软件试下
若遇到pytesseract.pytesseract.TesseractError: (1, ‘Error opening data file \Program Files (x86)\Tesseract-OCR\eng.traineddata Please make sure the TESSDATA_PREFIX environment variable is set
to your “tessdata” directory. Failed loading language ‘eng’ Tesseract couldn’t load any languages! Could not initialize tesseract.’)
解决方法:
在系统变量中新增一个变量TESSDATA_PREFIX,使该变量的值为 D:\Program Files \Tesseract-OCR\tessdata 该路径值















 3453
3453










 暂无认证
暂无认证















 到【灌水乐园】发言
到【灌水乐园】发言










weixin_47729409: 你这程序有错误
古月哥欠666: qzpz
海棠听风~: 作者你好,我想scoring一般那个指标进行评估啊
chengzi123123123: share=True
谙橘-懒虫: 请问有pdf的那个网盘提取码是什么呀