南京大学学报(自然科学版) ›› 2022, Vol. 58 ›› Issue (3): 420–429.doi: 10.13232/j.cnki.jnju.2022.03.006
• • 上一篇
深度强化学习结合图注意力模型求解TSP问题
王扬, 陈智斌(  ), 杨笑笑, 吴兆蕊
), 杨笑笑, 吴兆蕊
- 昆明理工大学理学院,昆明,650000
Deep reinforcement learning combined with graph attention model to solve TSP
Yang Wang, Zhibin Chen(), Xiaoxiao Yang, Zhaorui Wu
- Faculty of Science,Kunming University of Science and Technology,Kunming,650000,China
PDF (PC)
1806摘要/Abstract
摘要:
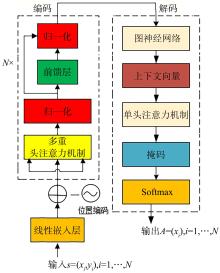
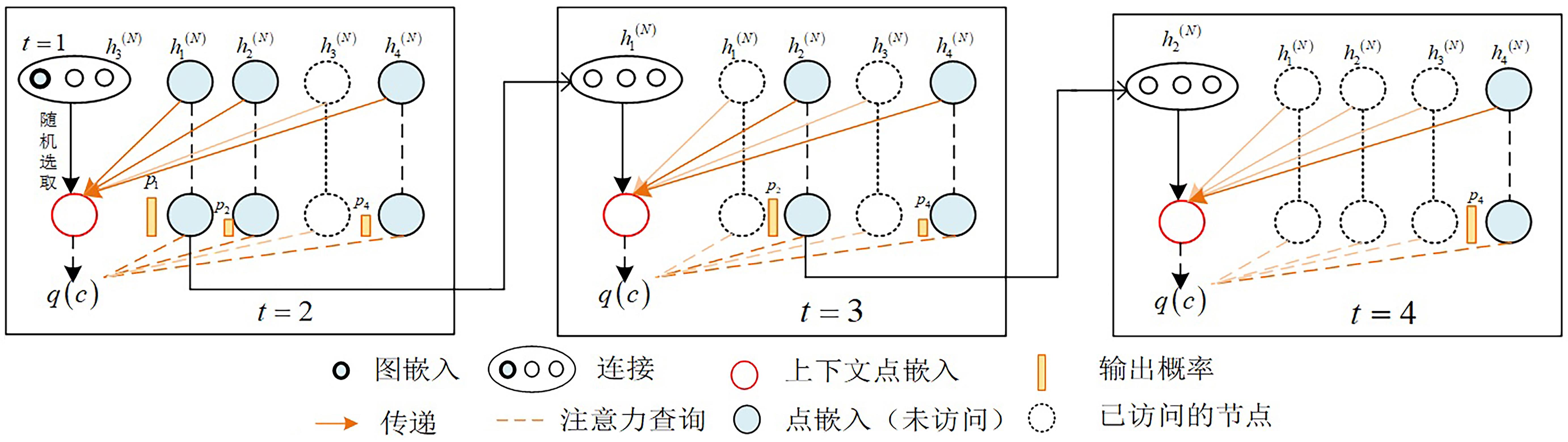
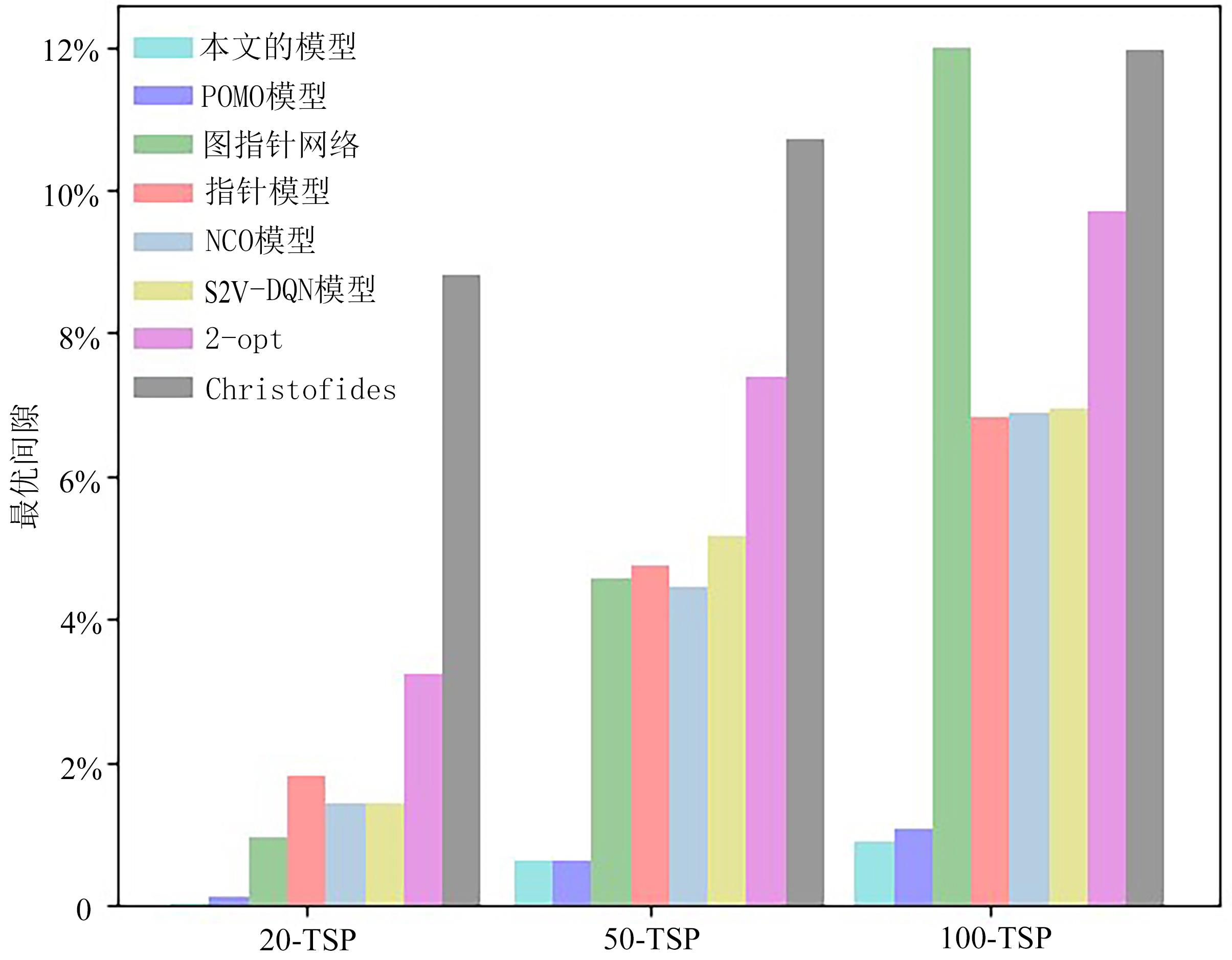
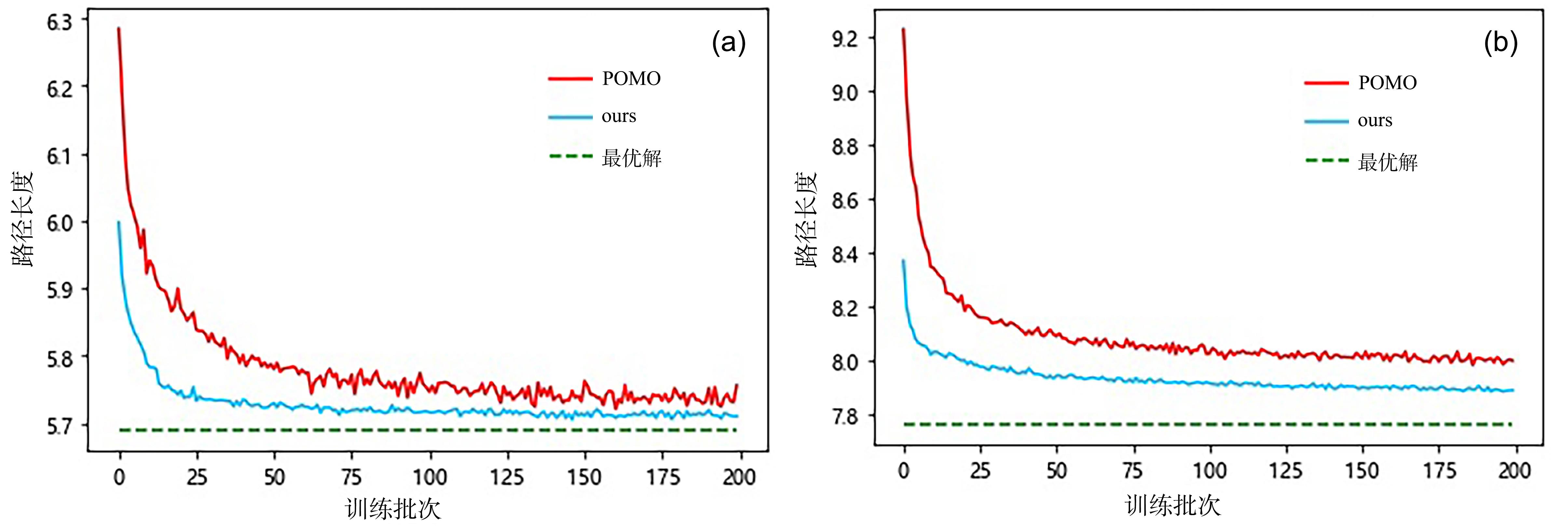
旅行商问题(Traveling Salesman Problem,TSP)是组合最优化问题(Combinatorial Optimization Problem,COP)中的经典问题,多年以来一直被反复研究.近年来深度强化学习(Deep Reinforcement Learning,DRL)在无人驾驶、工业自动化、游戏等领域的广泛应用,显示了强大的决策力和学习能力.结合DRL和图注意力模型,通过最小化路径长度求解TSP问题.改进REINFORCE算法,训练行为网络参数,可以有效地减小方差,防止局部最优;在编码结构中采用位置编码(Positional Encoding,PE),使多重的初始节点在嵌入的过程中满足平移不变性,可以增强模型的稳定性;进一步结合图神经网络(Graph Neural Network,GNN)和Transformer架构,首次将GNN聚合操作处理应用到Transformer的解码阶段,有效捕捉图上的拓扑结构及点与点之间的潜在关系.实验结果显示,模型在100?TSP问题上的优化效果超越了目前基于DRL的方法和部分传统算法.
中图分类号:
- O22
图/表 10







参考文献 27
| 1 | Cook W J, Cunningham W H, Pulleyblank W R,et al. Combinatorial optimization. New York,NY,USA:Wiley?Interscience,2010:11-22. |
| 2 | Papadimitriou C H. The Euclidean travelling salesman problem is NP?complete. Theoretical Computer Science,1977,4(3):237-244. |
| 3 | 林敏,刘必雄,林晓宇. 带Metropolis准则的混合离散布谷鸟算法求解旅行商问题. 南京大学学报(自然科学),2017,53(5):972-983. |
| Lin M, Liu B X, Lin X Y. Hybrid discrete cuckoo search algorithm with metropolis criterion for traveling salesman problem. Journal of Nanjing University (Natural Science),2017,53(5):972-983. | |
| 4 | Bengio Y, Lodi A, Prouvost A. Machine learning for combinatorial optimization:A methodological tour d'horizon. European Journal of Operational Research,2021,290(2):405-421. |
| 5 | Kwon Y D, Choo J, Kim B,et al. POMO:Policy optimization with multiple optima for reinforcement learning. 2020,arXiv:. |
| 6 | Vaswani A, Shazeer N, Parmar N,et al. Attention is all you need∥Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook,NY,USA:Curran Associates Inc.,2017,30:6000-6010. |
| 7 | Li Y X. Deep reinforcement learning:An overview. 2017,arXiv:. |
| 8 | Optimization I G. Gurobi optimizer reference manual. https:∥www.gurobi.com,2015. |
| 9 | Applegate D L, Bixby D E, Chvatal V,et al. The traveling salesman problem:A computational study. Interfaces,2008,38(4):344-345. |
| 10 | Christofides N. Worst?case analysis of a new heuristic for the travelling salesman problem. Pittsburgh,PA,USA:Carnegie?Mellon University,1976. |
| 11 | Johnson D S. Local optimization and the traveling salesman problem∥The 17th International Colloquium on Automata,Languages and Programming. Springer Berlin Heidelberg,1990:446-461. |
| 12 | Helsgaun K. An effective implementation of the Lin?Kernighan traveling salesman heuristic. European Journal of Operational Research,2000,126(1):106-130. |
| 13 | Vinyals M, Fortunato M, Jaitly N. Pointer networks∥Proceedings of the 29th International Conference on Neural Information Processing System. Cambridge,MA,USA:MIT Press,2015(28):2692-2700. |
| 14 | Bello I, Pham H, Le Q V,et al. Neural combinatorial optimization with reinforcement learning. 2017,arXiv:. |
| 15 | Deudon M, Cournut P, Lacoste A,et al. Learning heuristics for the TSP by policy gradient∥Proceedings of the 15th International Conference on the Integration of Constraint Programming,Artificial Intelligence and Operations Research. Springer Berlin Heidelberg,2018:170-181. |
| 16 | Nazari M, Oroojlooy A, Taká? M,et al. Reinforcement learning for solving the vehicle routing problem∥Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook,NY,USA:Curran Associates Inc.,2018(31):9861-9871. |
| 17 | Costa P R O D, Rhuggenaath J, Zhang Y Q,et al. Learning 2?opt heuristics for the traveling salesman problem via deep reinforcement learning∥Proceedings of the 12th Asian Conference on Machine Learning. Bangkok,Thailand:JMLR,2020:465-480. |
| 18 | Dai H J, Khalil E B, Zhang Y Y,et al. Learning combinatorial optimization algorithms over graphs∥Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook,NY,USA:Curran Associates Inc.,2017,30:6351-6361. |
| 19 | Kool W, Van Hoof H, Attention Welling M.,learn to solve routing problems. 2019,arXiv:. |
| 20 | Chen X Y, Tian Y D. Learning to perform local rewriting for combinatorial optimization∥Proceedings of the 33rd Neural Information Processing Systems. Vancouver,Canada:NIPS,2019:6278-6289. |
| 21 | Li K W, Zhang T, Wang R. Deep reinforcement learning for multiobjective optimization. IEEE Transactions on Cybernetics,2020,51(6):3103-3114. |
| 22 | Wu Y X, Song W, Cao Z G,et al. Learning improvement heuristics for solving routing problems. IEEE Transactions on Neural Networks and Learning Systems,2021:1-13. |
| 23 | Xin L, Song W, Cao Z G,et al. Multi?decoder attention model with embedding glimpse for solving vehicle routing problems∥Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto,CA,USA:AAAI Press,2021:12042-12049. |
| 24 | Scarselli F, Gori M, Tsoi A C,et al. The graph neural network model. IEEE Transactions on Neural Networks,2008,20(1):61-80. |
| 25 | Williams R J. Simple statistical gradient?following algorithms for connectionist reinforcement learning. Machine Learning,1992,8(3):229-256. |
| 26 | Ho Y, Wookey S. The real?world?weight cross?entropy loss function:Modeling the costs of mislabeling. IEEE Access,2019(8):4806-4813. |
| 27 | Ma Q, Ge S W, He D Y,et al. Combinatorial optimization by graph pointer networks and hierarchical reinforcement learning. 2019,arXiv:. |
相关文章 3
| [1] | 徐樱笑, 资文杰, 宋洁琼, 邵瑞喆, 陈浩. 基于多站点、多时间注意力机制的电磁强度时空关联分析与可视化[J]. 南京大学学报(自然科学版), 2021, 57(5): 838-846. |
| [2] | 刘玲珊, 熊轲, 张煜, 张锐晨, 樊平毅. 信息年龄受限下最小化无人机辅助无线供能网络的能耗:一种基于DQN的方法[J]. 南京大学学报(自然科学版), 2021, 57(5): 847-856. |
| [3] | 林 敏*,刘必雄,林晓宇. 带Metropolis准则的混合离散布谷鸟算法求解旅行商问题[J]. 南京大学学报(自然科学版), 2017, 53(5): 972-. |
Metrics
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
Cited |
||||||
| Shared | ||||||
| Discussed | ||||||
本文评价
推荐阅读 0
|
||