SQL and Machine Learning have a few things in common. It’s easy to start with one as it doesn’t require a lot of coding. Also, code rarely crashes.
I would argue that the fact that the SQL queries don’t crash makes the Data Analysis even harder. How many datasets I’ve extracted from the database, that turned out to have wrong or missing data? Many!
If the code would simply crash, I’d know I screw it up. Data Scientists need to spend a considerable amount of time on data validation because an SQL query always returns something.
These are the 5 mistakes you should avoid when writing SQL queries.
A few topics that might interest you:
- Labeling and Data Engineering for Conversational AI and Analytics- Data Science for Business Leaders [Course]- Intro to Machine Learning with PyTorch [Course]- Become a Growth Product Manager [Course]- Deep Learning (Adaptive Computation and ML series) [Ebook]- Free skill tests for Data Scientists & Machine Learning Engineers
Some of the links above are affiliate links and if you go through them to make a purchase I’ll earn a commission. Keep in mind that I link courses because of their quality and not because of the commission I receive from your purchases.
In case you’ve missed my previous article about this topic:
5 mistakes when writing SQL queries
Don’t repeat my mistakes with writing SQL queries
towardsdatascience.com
1. Not knowing in what order queries execute

SQL has a low barrier to entry. You start writing queries — use a JOIN here and there, do some grouping and you’re already an expert (at least some people think so).
But does the so-called expert even know in what order do SQL queries execute?
SQL queries don’t start with SELECT — they do in the editor when we write them, but the database doesn’t start with SELECT.
The database starts executing queries with FROM and JOIN. That’s why we can use fields from JOINed tables in WHERE.
Why can’t we filter the result of GROUP BY in WHERE? Because GROUP BY executes after WHERE. Hence, the reason for HAVING.
At last, we come to SELECT. It selects which columns to include and defines which aggregations to calculate. Also, Window Functions execute here.
This explains why we get an error when we try to filter with the output of a Window Function in WHERE.
Note, databases use a query optimizer to optimize the execution of a query. The optimizer might change the order of some operations so that the query runs faster. This diagram is a high-level overview of what is happening behind the scenes.
2. What do Window Functions actually do?
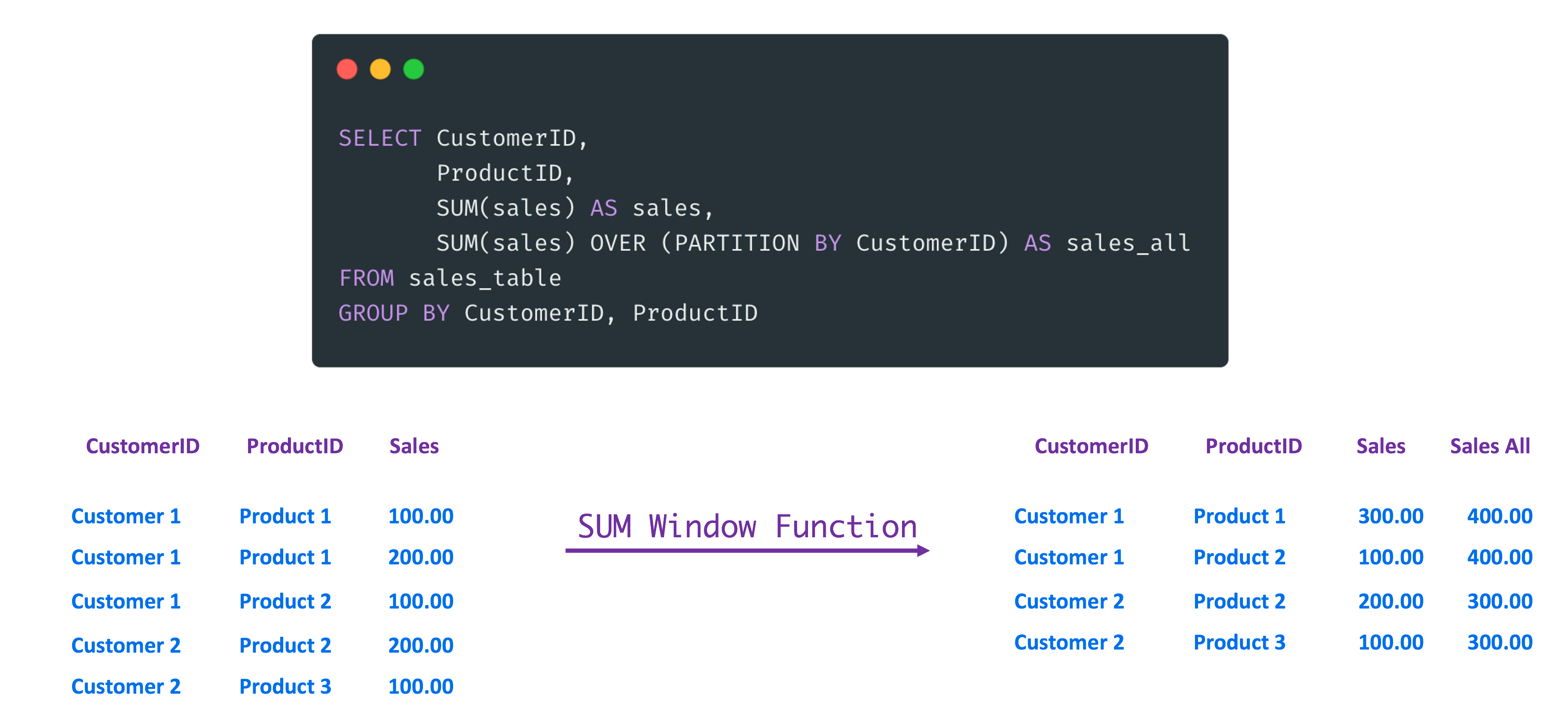
Window Functions seemed cryptic to me when I first encountered them. Why use Window Functions as GROUP BY can aggregate the data?
Well, a Window Function (WF) simplifies many operations when designing queries:
- WF allows access to the records right before and after the current record. See Lead and Lag functions.
- WF can perform an additional aggregation on already aggregated data with GROUP BY. See the example in the image above, where I calculate sales all with a WF.
- ROW_NUMBER WF enumerates the rows. We can also use it to remove duplicate records with it. Or to take a random sample.
- As the name suggests WF can calculate statistics on a given window:
sum(sales) OVER (PARTITION BY CustomerID BY ts ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as cumulative_sum
The WF above would calculate the cumulative sum from the first record to the current record.
Where did I do a mistake with Window Functions?
I didn’t take the time for a tutorial that would explain the basics and the power of Window Functions. Consequently, I avoided them and the queries became overcomplicated. Then bugs creep in.
Run the example above
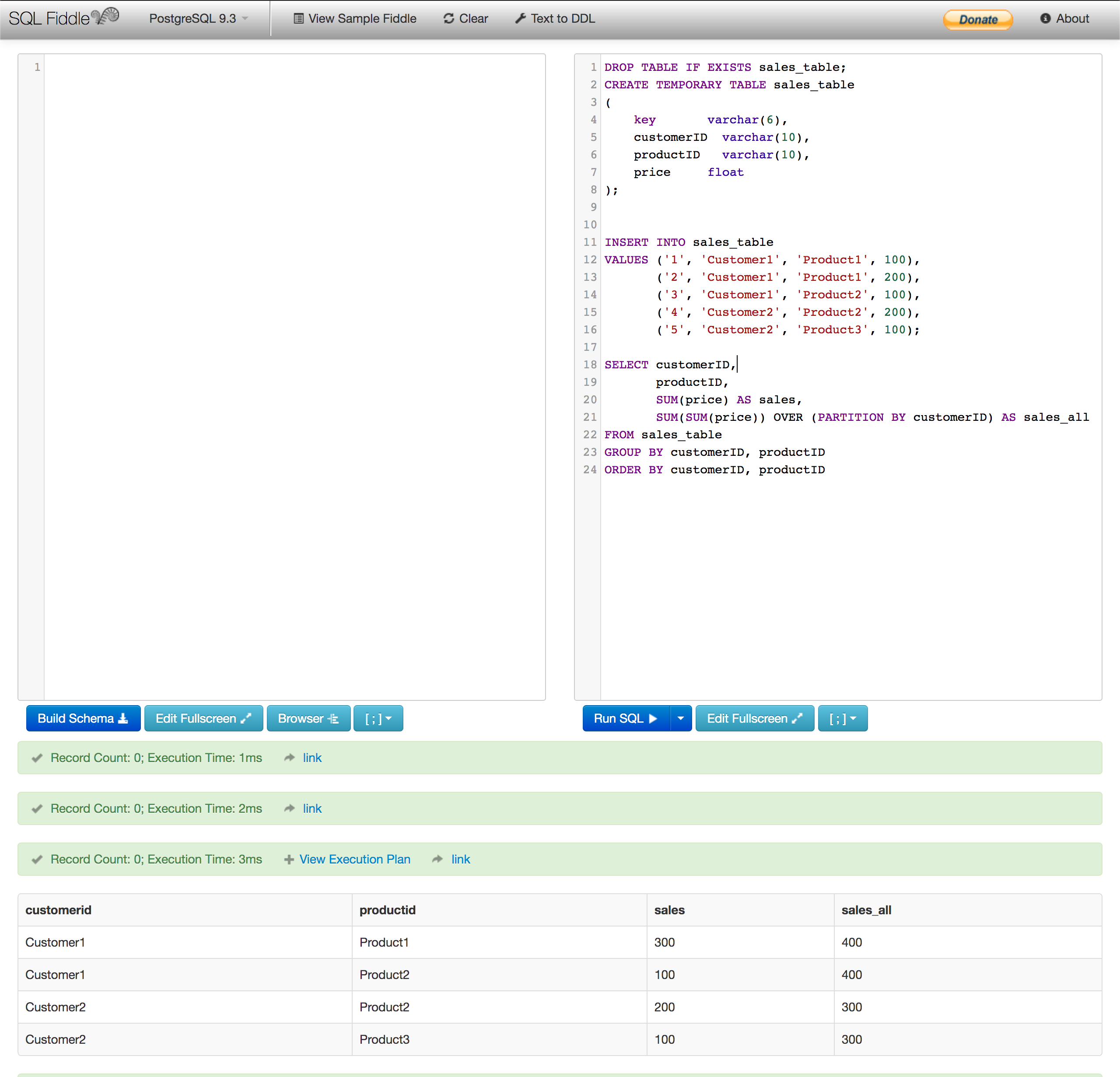
I got many requests from readers that would like to play with the example above. Now, you can run the example online in SQL Fiddle.
Here is the code, if you’d like to try it in your local database (it should work with PostgreSQL 9.3):
DROP TABLE IF EXISTS sales_table; CREATE TEMPORARY TABLE sales_table ( key varchar(6), customerID varchar(10), productID varchar(10), price float );INSERT INTO sales_table VALUES ('1', 'Customer1', 'Product1', 100), ('2', 'Customer1', 'Product1', 200), ('3', 'Customer1', 'Product2', 100), ('4', 'Customer2', 'Product2', 200), ('5', 'Customer2', 'Product3', 100);SELECT customerID, productID, SUM(price) AS sales, SUM(SUM(price)) OVER (PARTITION BY customerID) AS sales_all FROM sales_table GROUP BY customerID, productID ORDER BY customerID, productID
3. Calculating average with CASE WHEN6
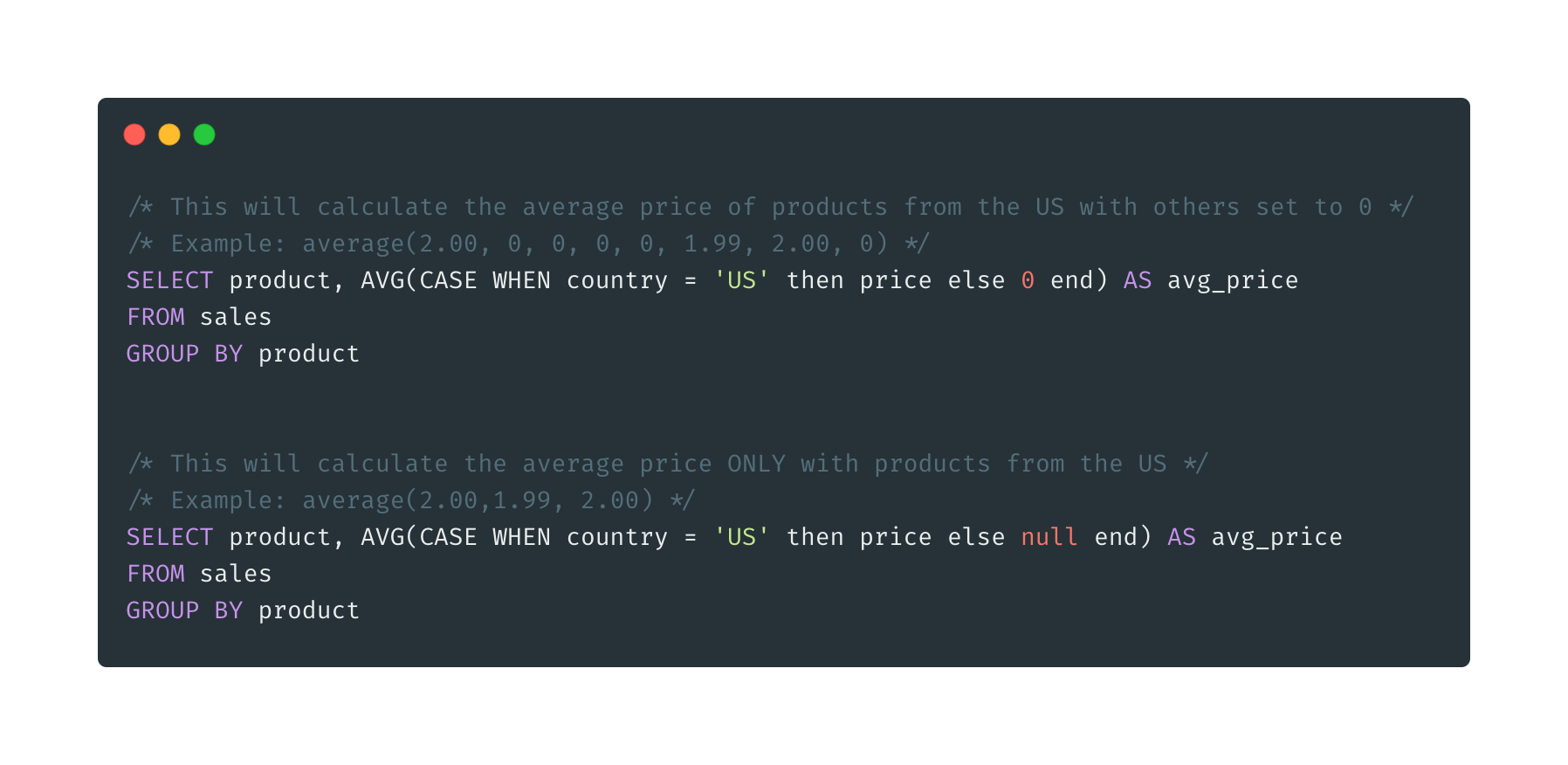
CASE WHEN is like an IF statement in a programming language. It is useful when we need to calculate a statistic on a certain subset of the data.
In the image above, I calculate an average price for products sold in the US. I wasn’t careful with the ELSE in the CASE WHEN.
In the first example, I use 0 for all products that are not from the US, which lowers the overall average price. If there would be many non-US products, the average could get close to 0.
SELECT product, AVG(CASE WHEN country = 'US' then price else 0 end) AS avg_price
FROM sales
GROUP BY product
In the second example, I calculate the average price only with products that are sold in the US, which is usually what we want.
Note, you don’t need to include ELSE when using CASE WHEN as it defaults to NULL.
SELECT product, AVG(CASE WHEN country = 'US' then price else null end) AS avg_price
FROM sales
GROUP BY product
The key takeaway is that you should be careful with “else 0” when using CASE WHEN. It doesn’t have any effect with SUM, but it has a huge effect on AVG.
4. JOINs ON columns with missing values

There are 4 different JOINs in SQL: Inner, Outer, Left and Right. When we use JOIN in a query, it defaults to an INNER join.
Luckily for me, I took the time and read a few tutorials about JOINs. But I still made a rookie mistake.
I wrote a query similar at its core to the query in the image above. When I was performing data validation, many records were missing. How is this possible? It is such a simple JOIN!
It turned out that many entries in the table 1 and table 2 had string_field column with NULL values. I thought that JOIN would keep records with NULL values because NULL is equal to NULL, isn’t it?
Then I tried:
SELECT NULL = NULL
It returns NULL.
The solution to getting all entries was to wrap string_field in COALESCE, which converts NULL to an empty string.
SELECT t1.*,
t2.price
FROM table1 AS t1
JOIN table2 AS t2
ON COALESCE(t1.string_field, '') = COALESCE(t2.string_field, '')
But be careful as this JOINs each entry with the empty string from table1 with each entry with the empty string in table2.
One way to remove those duplicates is to use ROW_NUMBER() window function:
- I assume you have a unique identifier for each row “some_id” and a timestamp field.
- Simply wrap the query and take the first row for each unique identifier to remove duplicates.
SELECT *
FROM (
SELECT t1.*,
t2.price,
ROW_NUMBER() OVER(PARTITION by some_id ORDER BY timestamp_field) as row_count
FROM table1 AS t1
JOIN table2 AS t2
ON COALESCE(t1.string_field, '') = COALESCE(t2.string_field, '')
)
WHERE row_count = 1
5. Not using temporary tables for complex queries

SQL would be great if only we could debug queries. What if I told you can debug them!
You can breakdown a complex query and create multiple temporary tables. Then you can run “sanity check” queries against those tables to make sure they contain correct entries. I highly recommend this approach when designing a new non-trivial query or report.
DROP TABLE IF EXISTS trainset;
CREATE TEMPORARY TABLE trainset AS (
SELECT *
FROM table_1
WHERE field = 1
);
The only downside of temporary tables is that the query optimizer in the database cannot optimize the query.
When performance is needed I rewrite the queries defined with temporary tables to a query defined with WITH statement.
WITH helper_table1 AS ( SELECT * FROM table_1 WHERE field = 1 ),helper_table2 AS ( SELECT * FROM table_2 WHERE field = 1 ),helper_table3 AS ( SELECT * FROM helper_table1 as ht1 JOIN helper_table2 as ht2 ON ht1.field = ht2.field )SELECT * FROM helper_table3;