一种基于伪行伪列的水印处理和数据溯源方法与流程
本发明属于数据库安全
技术领域:
,尤其是一种基于伪行伪列的水印处理和数据溯源方法。
背景技术:
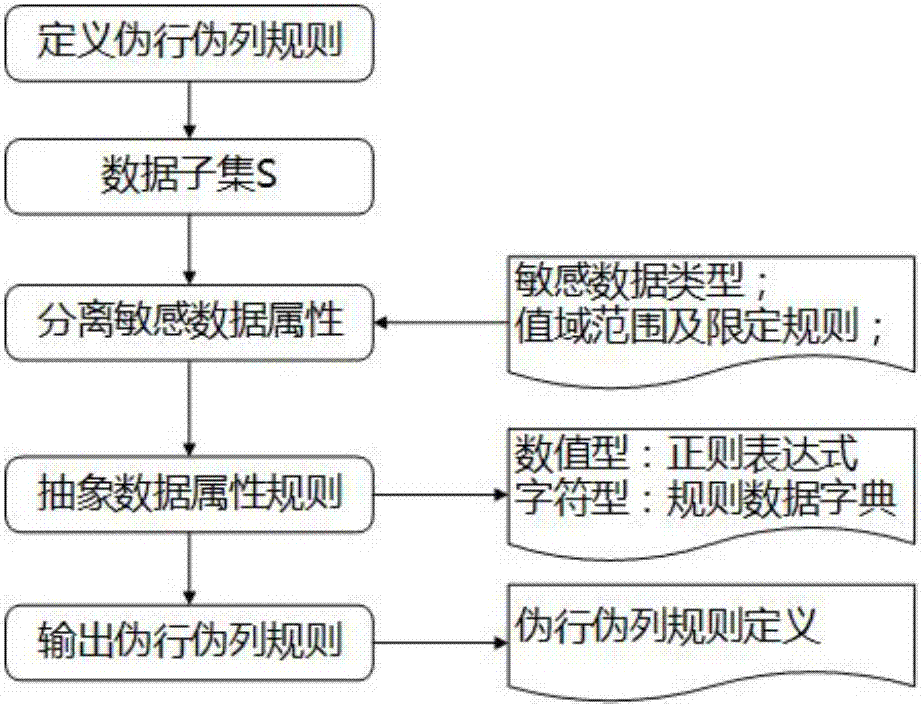
:数字水印技术是信息隐藏技术中的一种,它是将水印信息直接嵌入数字载体中,不影响原载体的使用,也不易被人察觉到。通过这些嵌入的信息能达到确认版权所有者、证明载体是否被篡改、追踪泄密用户的目的。数字水印技术主要研究集中在图像和音频等多媒体水印方面。随着关系型数据库的广泛应用,人们越来越关注数据库的版权保护,数据库水印技术的研究和发展具有较大的理论价值。数据库水印技术是数字水印技术中的一个重要的研究方向,它是将水印信息嵌入到数据库中,不影响数据库的正常使用,其在实现要求的层面上要高于多媒体中的水印技术,除了在嵌入数据库的过程中尽可能不修改原始数据或者较少的修改,从而不影响原始数据的使用价值,确保信息可以被用户正常使用,还需要在提取阶段可以基本上不受损的被发布者提取出来。目前基于数据库水印技术存在安全性较差、数据损失精度、容易受到破坏等问题。技术实现要素:本发明的目地在于克服现有技术的不足,提出一种安全性能高、数据损失小且不容易被破坏的基于伪行伪列的水印处理和数据溯源方法。本发明解决其技术问题是采取以下技术方案实现的:一种基于伪行伪列的水印处理和数据溯源方法,包括以下步骤:步骤1、数据库初始化步骤:根据发现规则对数据进行自动发现,抽取指定的数据集合,生成数据子集;步骤2、对生成的数据子集进行水印处理步骤:添加伪行数据、伪列数据并根据字段规则特征实现数据水印的嵌入,生成带有水印标记的数据。在步骤2后还包括数据溯源处理步骤:输入样本数据进行水印提取,并根据水印标记进行数据溯源。所述步骤1生成的数据子集为:数据库表包含有多个元组,每个元组的数据模式可以用r=(pk,f1,f2…fn,fk),其中r代表元组,pk代表主键,fk为外键,f1,f2…fn为属性;定义c为数据库中包含敏感属性的表的集合,对c进行数据抽取形成数据子集s,s中含有一个或多个表。所述步骤2的具体实现方法包括以下步骤:步骤2-1、定义伪行伪列字段规则:字段规则根据敏感数据属性含义和数据类型进行定义;步骤2-2、选择数据子集s中一个或多个表的属性,进行伪行字段或者伪列字段规则配置:增加的伪行数据或伪列数据按照指定的字段规则生成;步骤2-3、根据选择的字段规则,进行水印数据的生成和数据嵌入;伪行水印处理根据字段规则配置生成数据行,指定的字段类型与字段规则对应匹配,生成的数据根据规则特征嵌入水印标记;伪列水印处理根据字段规则配置生成数据列,并根据指定的规则特征嵌入水印标记;由此完成数据水印标记的嵌入;步骤2-4、在伪行水印处理时对嵌入水印的数据行根据离散分布的方式将生成的水印数据插入到原始数据中;在伪列水印处理时添加生成的列,然后将嵌入水印的数据插入到新的列中。所述步骤2-1定义伪行伪列字段规则的具体方法为:首先分离出敏感数据属性,根据敏感数据属性的类型、值域范围及限定规则,抽象出敏感数据属性的特征,数据值型数据通过正则表达式方式抽取数据属性规则,字符型属性通过正则表达式方式或进行值域范围分解抽取数据属性规则。所述步骤2-2的具体实现方法为:选择指定的表并根据表中的已有字段属性分布情况,选择采用伪行或伪列方式嵌入水印信息;在选择伪行时,对表中已有字段属性进行规则定义,选择字段属性配置对应的伪行字段规则;在选择伪列时,直接配置对应的伪列字段规则,生成的数据行比例与原始数据一致。所述步骤3的具体实现方法包括如下步骤:步骤3-1、按抽样比例读取数据表中的数据,对抽样数据进行自动特征识别,将符合特征数据进行缓存;步骤3-2、将缓存的数据进行水印标记的提取,提取结果与记录的水印标记数据进行比对,比对结果一致性达到一定比例时,确定数据水印的提取完成;步骤3-3、根据水印标记,查询数据溯源信息。本发明的优点和积极效果是:本发明对原始数据进行无损水印数据生成,不影响数据的正常使用;通过伪行伪列数据水印方法有效解决了结构化数据的水印嵌入;数据溯源具有更好的抗攻击能力,在数据遭到局部破坏时不影响数据的整体溯源能力;本发明能够提高数据共享过程中的安全防护能力,实现数据水印的嵌入和泄露数据的溯源,具有安全性能高、数据损失小且不容易被破坏等特点,因此在数据库安全领域具有广泛的应用场景。附图说明图1是本发明的处理流程图;图2是本发明中定义伪行伪列规则的示意图;图3是本发明中伪行伪列水印处理方法的示意图;图4是本发明中数据溯源方法的示意图。具体实施方式以下结合附图对本发明实施例做进一步详述。一种基于伪行伪列的水印处理和数据溯源方法,如图1所示,包括以下步骤:步骤1、数据库初始化:根据发现规则对数据进行自动发现,抽取指定的数据集合,生成数据子集。数据库表包含有多个元组,每个元组的数据模式可以用r=(pk,f1,f2…fn,fk),其中r代表元组,pk代表主键,fk为外键,f1,f2…fn为属性;在属性中会包含有部分敏感信息,定义c为数据库中包含敏感属性的表的集合,对c进行数据抽取形成数据子集s,s中含有一个或多个表,s中表的属性含有敏感信息,s中表之间具有一定的关系,比如主外键表。以人员身份信息数据库为例进行说明,其数据结构如下表:列名数据类型长度描述idnumber10编号namevarchar230姓名personidvarchar218身份证号birthdaydate8出生日期sexnumber1性别telphohevarchar215电话在对上述数据库进行初始化时,通过规则发现表中的数据类型和数据特征,将name、personid、telphohe等作为敏感数据。步骤2、对步骤1生成的数据子集进行水印处理:添加伪行数据、伪列数据并根据字段规则特征实现数据水印的嵌入,生成带有水印标记的数据。具体方法如下:步骤2-1、定义伪行伪列字段规则。如图2所示,字段规则根据敏感数据属性含义和数据类型进行定义;敏感数据属性定义会根据数据属性含义和数据类型结合,敏感数据属性往往具有明显的数据特征和数据类型;首先分离出敏感数据属性,根据敏感数据属性的类型、值域范围及限定规则,抽象出敏感数据属性的特征,数据值型数据将通过正则表达式方式抽取数据属性规则,字符型属性可通过正则表达式方式或进行值域范围分解抽取数据属性规则。数据属性规则抽取完成后形成两类属性规则,一类是通过正则表达式定义的属性规则,一类是通过值域分解得到的数据字典属性规则;伪行伪列字段规则定义根据抽象出来的正则表达式属性规则和数据字典属性规则。在本实施例中,依据表的字段属性类型,列出伪行水印规则进行伪行字段规则配置,分别对应name、personid、telphohe三个字段配置伪行字段规则,伪行字段规则与表中的字段属性类型和含义要一一对应。步骤2-2、选择数据子集s中一个或多个表的属性,进行伪行字段或者伪列字段规则配置。首先选择指定的表,根据表中的已有字段属性分布情况,选择采用伪行或伪列方式嵌入水印信息;选择伪行时,对表中已有字段属性进行规则定义,选择字段属性配置对应的伪行字段规则,由于表中字段属性会很多,限制至少两个字段属性需要配置,其余字段属性按默认值,配置生成的数据行比例,如按按%1比例配置;选择伪列时,直接配置对应的伪列字段规则,生成的数据行比例与原始数据一致。步骤2-3、根据选择的字段规则,进行水印数据的生成。伪行或伪列水印处理根据字段规则配置生成数据行或数据列,生成的数据中对应规则配置的数值型数据按正则表达式构建数据值,并通过随机数值组合生成水印标记信息并嵌入到数据值中;字符型数据按值域范围获取数据字典数据构建数据值,并通过值域数据字典对应的数值编码生成水印标记信息并嵌入到数据值中。在本步骤中,本实施例根据name属性值域特征按照name数据字典方式嵌入水印标记;根据personid、telphohe属性类别特征,按照正则表达式和随机数组合方式嵌入水印标记。步骤2-4、水印数据的插入处理。如图3所示,在伪行水印处理时,按照配置的数据行比例,在原始数据中按照一定的行间隔将水印数据分散的插入到原始数据中;在伪列水印处理时,对原始数据增加新的字段属性并根据配置生成字段名称,然后将伪列数据插入到对应的字段属性中,从而生成数据水印文件。步骤3、针对步骤1至步骤2所述方法实现水印处理后输出的数据进行数据溯源。如图4所示,具体方法如下:步骤3-1、设定数据表中的数据由外部数据导入形成,抽样比例可以根据数据量大小进行设定;对抽样数据进行数据抽取,数据抽取后进行自动数据特征识别,识别依据水印处理时嵌入数据的类型和数据值特征;将符合特征的数据进行缓存;步骤3-2、将缓存的数据进行水印标记的提取,根据数据类型和数据特征进行规则化,按照生成水印的方式对数据进行水印标记信息的逐个提取,然后将提取结果与记录的水印数据进行比对,比对结果一致时再进行下一组数据的提取和比对,所有的比对结果一致性达到一定比例时(例如30%),确定数据水印的提取完成;如果比对结果不能满足最低的一致性比例,数据水印的提取结果将根据已经提取出的结果进行验证提取,即增加更多的数据进行特征识别和水印标记的提取,从而完成水印标记的提取;步骤3-3、根据提取的水印标记,查询数据溯源信息;数据溯源信息中含有数据所有者及相关信息。从而完成人员身份信息的数据溯源。需要强调的是,本发明所述的实施例是说明性的,而不是限定性的,因此本发明包括并不限于具体实施方式中所述的实施例,凡是由本领域技术人员根据本发明的技术方案得出的其他实施方式,同样属于本发明保护的范围。当前第1页12
完整全部详细技术资料下载
当前第1页 1 2
相关技术
- 一种代码加密、解密方法及装置...
- 一种软件安全加固方法与流程
- 一种基于动态链接库的Java...
- 基于对称不确定性和信息交互增...
- 基于共表达网络的癌症靶向标志...
- 分子对接方法及系统与流程
- 针对生物信号的质量评价设备、...
- 一种基于虚拟边界力法的弧板式...
- 一种适用于圆导体绕组高频损耗...
- 一种组合空气间隙击穿电压预测...
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
防伪水印制作相关技术
- 包线一压防伪纤维及其制作方法和使用方法
- 一种点印防伪液层的防伪章装置的制造方法
- 一种防水印台的制作方法
- 一种防伪花纸及其印制方法
- 一种彩色水印防伪纸及其生产方法
- 带水印支撑结构的网笼及其制造的防伪纸的制作方法
- 白水印模片、白水印网笼及其制备的防伪纸的制作方法
- 一种抗几何攻击的视频水印防伪方法
- 一种抗数模模数变换过程的数字水印防伪方法
- 数字水印防伪印刷品检测装置的制作方法
防伪水印相关技术
- 一种光学变色防伪颜料的制作方法
- 一种实时隐藏拍摄防伪水印的视频监控装置的制造方法
- 基于数字水印和图形码的产品防伪方法及装置的制造方法
- 基于数字水印和图形码的产品防伪方法及装置的制造方法
- 一种具有潜影水印的防伪纸张以及该纸张的制作工艺的制作方法
- 一种含有亮窗水印的防伪纸及其制造方法
- 一种化学水印防伪纸的制作方法
- 反铁磁共振标识的互联网查询验证方法
- 反铁磁共振标识的条码识别终端及其识读方法
- 一种防伪纸及其制造方法
防伪水印纸相关技术
- 一种防伪纸及其制造方法
- 在防伪纸基质中产生具有一定范围的透镜的透明的聚合物视窗的制作方法
- 一种漏空带金银线防伪纸、塑料包装防伪标袋膜及其加工方法
- 隐形图案防伪纸的制作方法
- 具有水印和防伪线的有价和防伪元件的制作方法
- 防伪口花纸及其制备方法
- 一种防伪纸的制作方法
- 纸面潜入对应信息防伪方法及制得的标识和标识制备方法
- 全息纸信息防伪标的制作方法
- 一种雅纸的数字水印防伪方法