
Mutual Mean-Teaching:为无监督学习提供更鲁棒的伪标签

本文介绍一篇我们发表于ICLR-2020的论文《Mutual Mean-Teaching: Pseudo Label Refinery for Unsupervised Domain Adaptation on Person Re-identification》[1],其旨在解决更实际的开放集无监督领域自适应问题,所谓开放集指预先无法获知目标域所含的类别。这项工作在多个行人重识别任务上验证其有效性,精度显著地超过最先进技术13%-18%,大幅度逼近有监督学习性能。这也是ICLR收录的第一篇行人重识别任务相关的论文,代码和模型均已公开。
论文链接: https://openreview.net/forum?id=rJlnOhVYPS
代码链接: https://github.com/yxgeee/MMT
视频介绍:
背景简介
任务
行人重识别(Person ReID)旨在跨相机下检索出特定行人的图像,被广泛应用于监控场景。如今许多带有人工标注的大规模数据集推动了这项任务的快速发展,也为这项任务带来了精度上质的提升。然而,在实际应用中,即使是用大规模数据集训练好的模型,若直接部署于一个新的监控系统,显著的领域差异通常会导致明显的精度下降。在每个监控系统上都重新进行数据采集和人工标注由于太过费时费力,也很难实现。所以无监督领域自适应(Unsupervised Domain Adaptation)的任务被提出以解决上述问题,让在有标注的源域(Source Domain)上训练好的模型适应于无标注的目标域(Target Domain),以获得在目标域上检索精度的提升。值得注意的是,有别于一般的无监督领域自适应问题(目标域与源域共享类别),行人重识别的任务中目标域的类别数无法预知,且通常与源域没有重复,这里称之为开放集(Open-set)的无监督领域自适应任务,该任务更为实际,也更具挑战性。
动机
无监督领域自适应在行人重识别上的现有技术方案主要分为基于聚类的伪标签法、领域转换法、基于图像或特征相似度的伪标签法,其中基于聚类的伪标签法被证实较为有效,且保持目前最先进的精度 [2,3],所以该论文主要围绕该类方法进行展开。基于聚类的伪标签法,顾名思义,(i)首先用聚类算法(K-Means, DBSCAN等)对无标签的目标域图像特征进行聚类,从而生成伪标签,(ii)再用该伪标签监督网络在目标域上的学习。以上两步循环直至收敛,如下图所示:
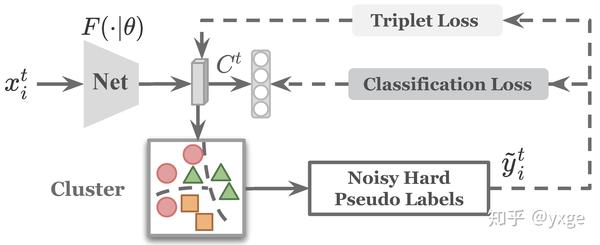

尽管该类方法可以一定程度上随着模型的优化改善伪标签质量,但是模型的训练往往被无法避免的伪标签噪声所干扰,并且在初始伪标签噪声较大的情况下,模型有较大的崩溃风险。所谓伪标签噪声主要来自于源域预训练的网络在目标域上有限的表现力、未知的目标域类别数、聚类算法本身的局限性等等。所以如何处理伪标签噪声对网络最终的性能产生了至关重要的影响,但现有方案并没有有效地解决它。
解决方法
概述
为了有效地解决基于聚类的算法中的伪标签噪声的问题,该文提出利用"同步平均教学"框架进行伪标签优化,核心思想是利用更为鲁棒的"软"标签对伪标签进行在线优化。在这里,"硬"标签指代置信度为100%的标签,如
文章被以下专栏收录

MMLab学术视野
PaperWeekly

RE-ID学习